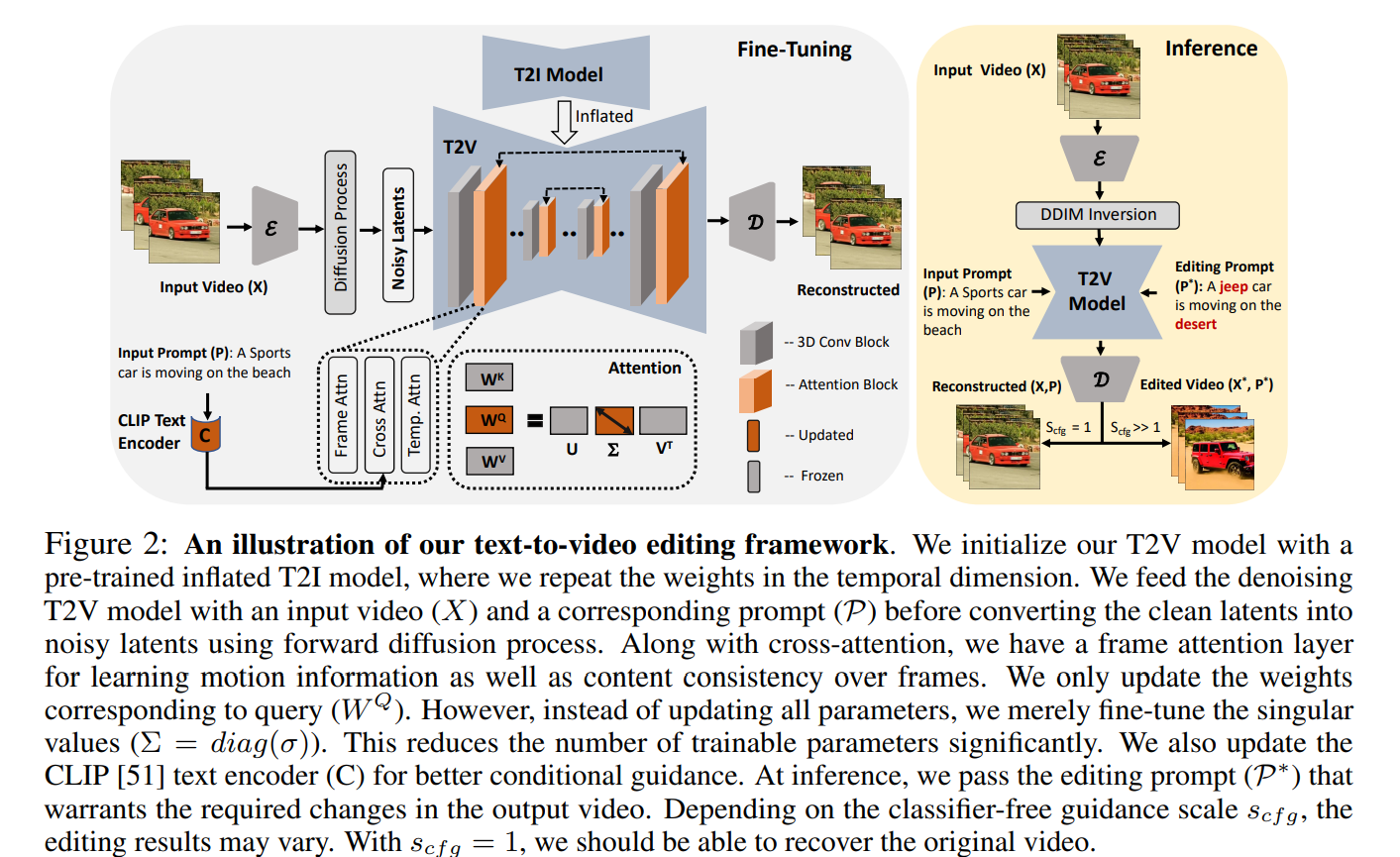
Text-to-Image (T2I) diffusion models have achieved remarkable success in synthesizing high-quality images conditioned on text prompts. Recent methods have tried to replicate the success by either training text-to-video (T2V) models on a very large number of text-video pairs or adapting T2I models on text-video pairs independently. Although the latter is computationally less expensive, it still takes a significant amount of time for per-video adaption. To address this issue, we propose SAVE, a novel spectral-shift-aware adaptation framework, in which we fine-tune the spectral shift of the parameter space instead of the parameters themselves. Specifically, we take the spectral decomposition of the pre-trained T2I weights and only control the change in the corresponding singular values, i.e. spectral shift, while freezing the corresponding singular vectors. To avoid drastic drift from the original T2I weights, we introduce a spectral shift regularizer that confines the spectral shift to be more restricted for large singular values and more relaxed for small singular values. Since we are only dealing with spectral shifts, the proposed method reduces the adaptation time significantly (∼ 10×) and has fewer resource constraints for training. Such attributes posit SAVE to be more suitable for real-world applications, e.g. editing undesirable contents during video streaming. We validate the effectiveness of SAVE with an extensive experimental evaluation under different settings, e.g. style transfer, object replacement, privacy preservation, etc. Code is available at https://github.com/nazmul-karim170/SAVE-Tex2Video.

@misc{karim2023save,
title={SAVE: Spectral-Shift-Aware Adaptation of Image Diffusion Models for Text-guided Video Editing},
author={Nazmul Karim and Umar Khalid and Mohsen Joneidi and Chen Chen and Nazanin Rahnavard},
year={2023},
eprint={2305.18670},
archivePrefix={arXiv},
primaryClass={cs.CV}
}